5 Ways to Crawl a Website
A Web crawler, sometimes called a spider, is an Internet bot that systematically browses the World Wide Web, typically for the purpose of Web indexing.
A Web crawler starts with a list of URLs to visit, called the seeds. As the crawler visits these URLs, it identifies all the hyperlinks in the page and adds them to the list of URLs to visit. If the crawler is performing archiving of websites it copies and saves the information as it goes. The archive is known as the repository and is designed to store and manage the collection of web pages. A repository is similar to any other system that stores data, like a modern-day database.
Let’s Begin!!
Metasploit
This auxiliary module is a modular web crawler, to be used in conjunction with wmap (someday) or standalone.
use auxiliary/crawler/msfcrawler msf auxiliary(msfcrawler) > set rhosts www.example.com msf auxiliary(msfcrawler) > exploit
From, the screenshot you can see it has loaded crawler in order to exact hidden file from any website, for example, about.php, jquery contact form, html and etc which is not possible to exact manually from the website using the browser. For information gathering of any website, we can use it.

Httrack
HTTrack is a free and open source Web crawler and offline browser, developed by Xavier Roche
It allows you to download a World Wide Web site from the Internet to a local directory, building recursively all directories, getting HTML, images, and other files from the server to your computer. HTTrack arranges the original site’s relative link-structure.
Type following command inside the terminal
httrack http://tptl.in –O /root/Desktop/file
It will save the output inside given directory /root/Desktop/file

From given screenshot you can observe this, it has dumb the website information inside it which consist html file as well as JavaScript and jquery.

Black Widow
This Web spider utility detects and displays detailed information for a user-selected Web page, and it offers other Web page tools.
BlackWidow’s clean, logically tabbed interface is simple enough for intermediate users to follow but offers just enough under the hood to satisfy advanced users. Simply enter your URL of choice and press Go. BlackWidow uses multi-threading to quickly download all files and test the links. The operation takes only a few minutes for small Web sites.
You can download it from here.
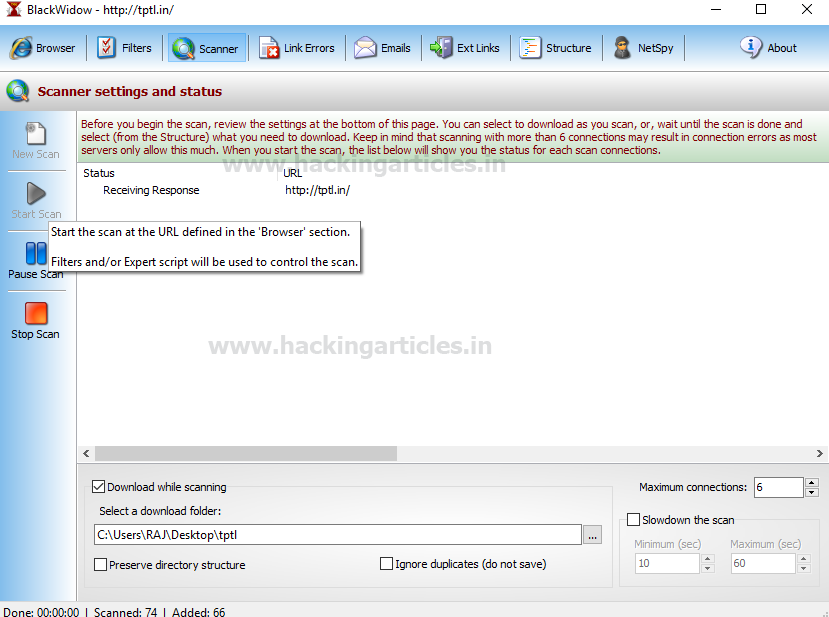
Enter your URL http://tptl.in in Address field and press Go.

Click on start button given on the left side to begin URL scanning and select a folder to save the output file.
From the screenshot, you can observe that I had browse C:\Users\RAJ\Desktop\tptl in order to store output file inside it.
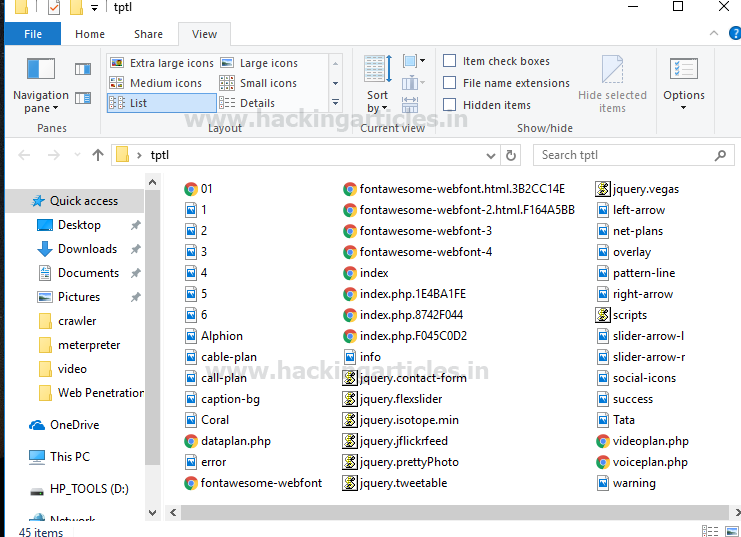
When you will open target folder tptl you will get entire data of website either image or content, html file, php file, and JavaScript all are saved in it.
Website Ripper Copier
Website Ripper Copier (WRC) is an all-purpose, high-speed website downloader software to save website data. WRC can download website files to a local drive for offline browsing, extract website files of a certain size and type, like the image, video, picture, movie, and music, retrieve a large number of files as a download manager with resumption support, and mirror sites. WRC is also a site link validator, explorer, and tabbed antipop-up Web / offline browser.
Website Ripper Copier is the only website downloader tool that can resume broken downloads from HTTP, HTTPS and FTP connections, access password-protected sites, support Web cookies, analyze scripts, update retrieved sites or files, and launch more than fifty retrieval threads.
You can download it from here.
Choose “websites for offline browsing” option.
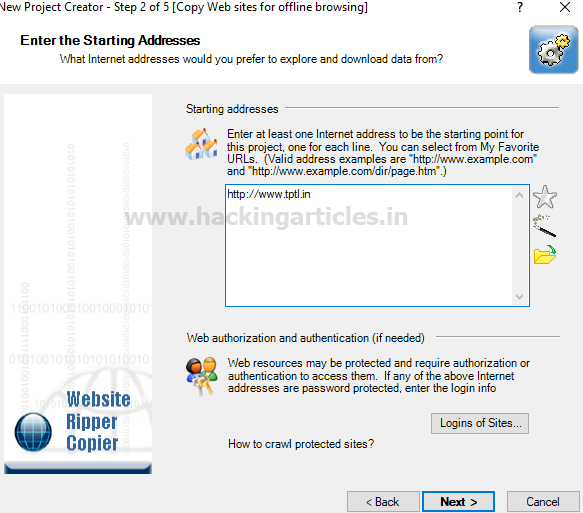
Enter the website URL as http://tptl.in and click on next.
Mention directory path to save the output result and click run now.

When you will open selected folder tp you will get fetched CSS,php,html and js file inside it.
Burp Suite Spider
Burp Spider is a tool for automatically crawling web applications. While it is generally preferable to map applications manually. You can use Burp Spider to partially automate this process for very large applications, or when you are short of time.
For more detail read our previous articles from here.
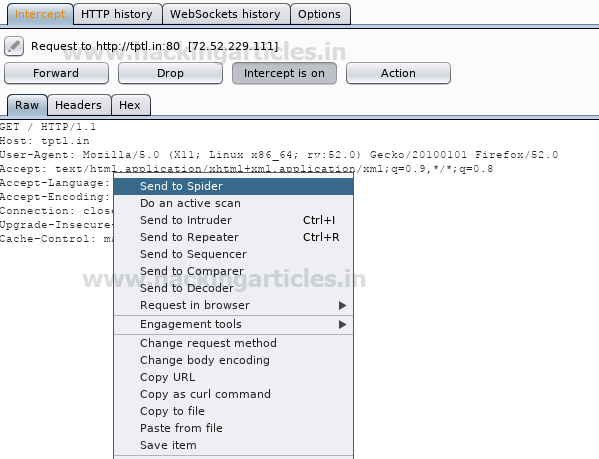
From given screenshot you can observe that I had fetched the http request of http://tptl.in. Now send to spider with help of action tab.
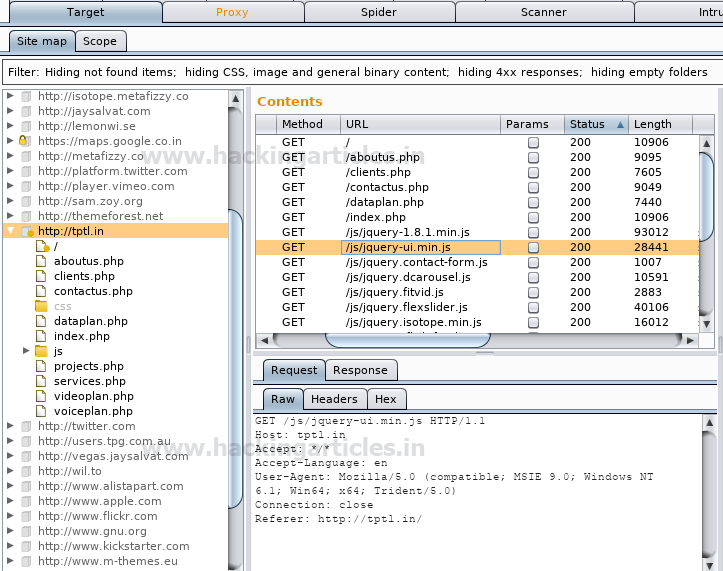
The targeted website has been added inside the site map under the target tab as a new scope for web crawling. From the screenshot, you can see it started web crawling of the target website where it has collected the website information in the form of php, html, and js.
To gain more knowledge about hacking tools. Click on this link.
Author: Aarti Singh is a Researcher and Technical Writer at Hacking Articles an Information Security Consultant Social Media Lover and Gadgets. Contact here
I am regular reader, how are you everybody? This piece of
writing posted at this web site is truly pleasant.
Based on how considerable your property game is, you’ll find likely to be distinct rules.
Nice Article
I appreciate, lead to I discovered exactly what I used to be looking for.
You have ended my four day lengthy hunt! God Bless you man. Have a great day.
Bye
Hello, thank you very much for learning your article, can I reprint your article